AI模型
AI模型是SuperTi平台为用户提供的一项便捷功能,可用于快速创建和部署AI模型实例。用户只需在导航栏中选择AI模型,即可浏览平台提供的开源模型库,并根据需求一键创建相应的模型实例。
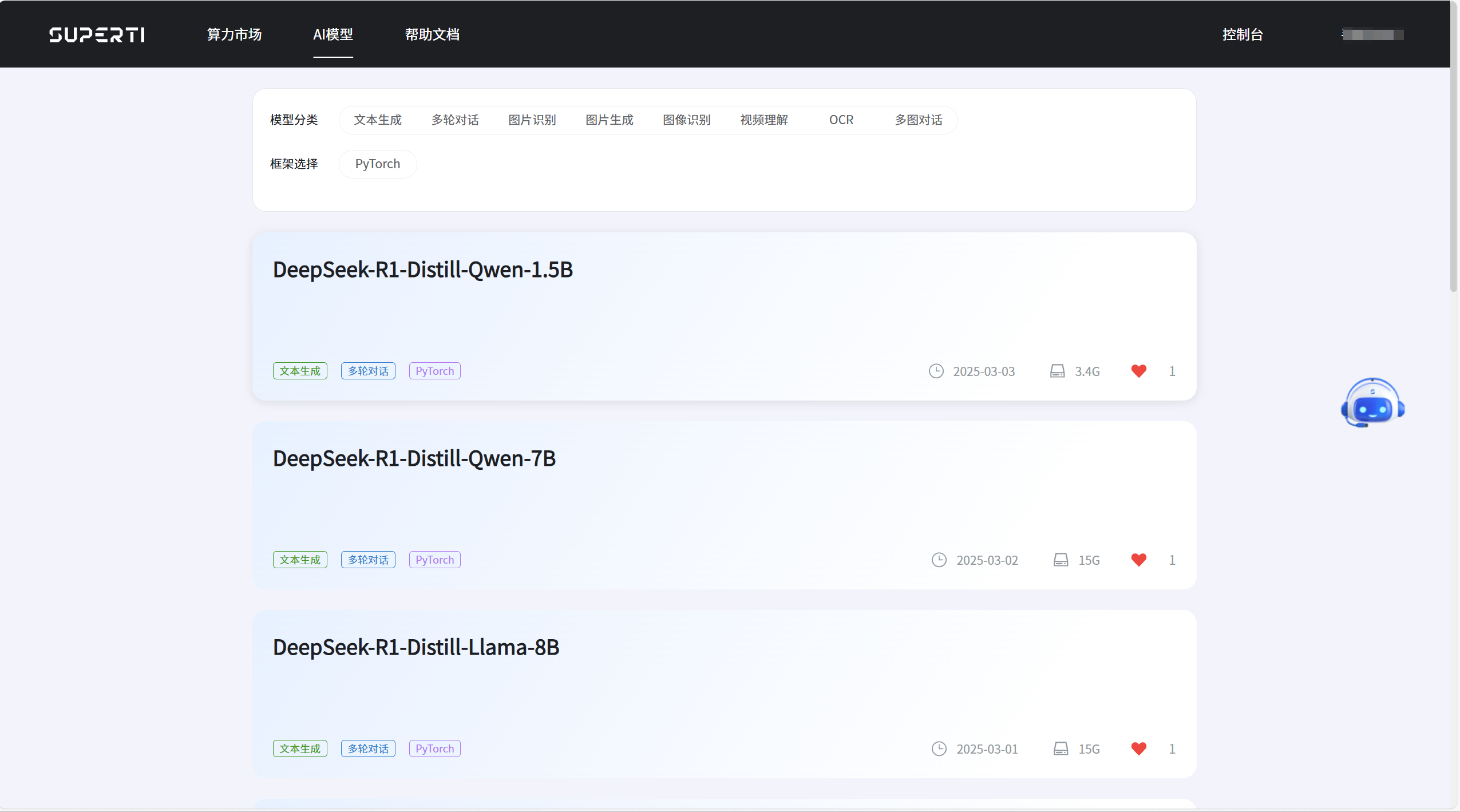
- 点击AI模型进入模型列表页面:
- 选择模型进入详情页面,创建实例:
通过创建模型实例可以直接选择服务器; 通过复制实例下载命令,用户可以在其他实例中按需下载该模型使用。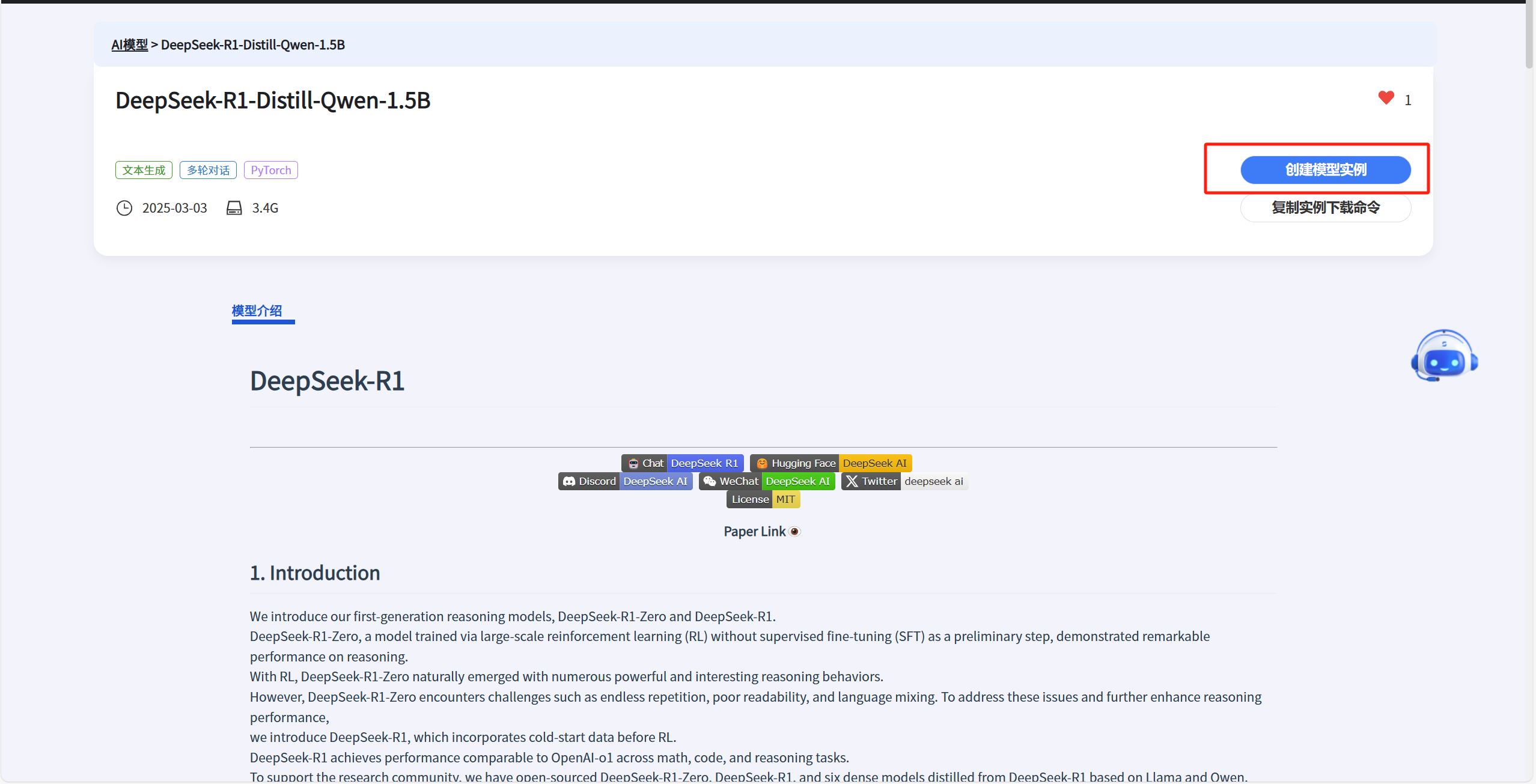
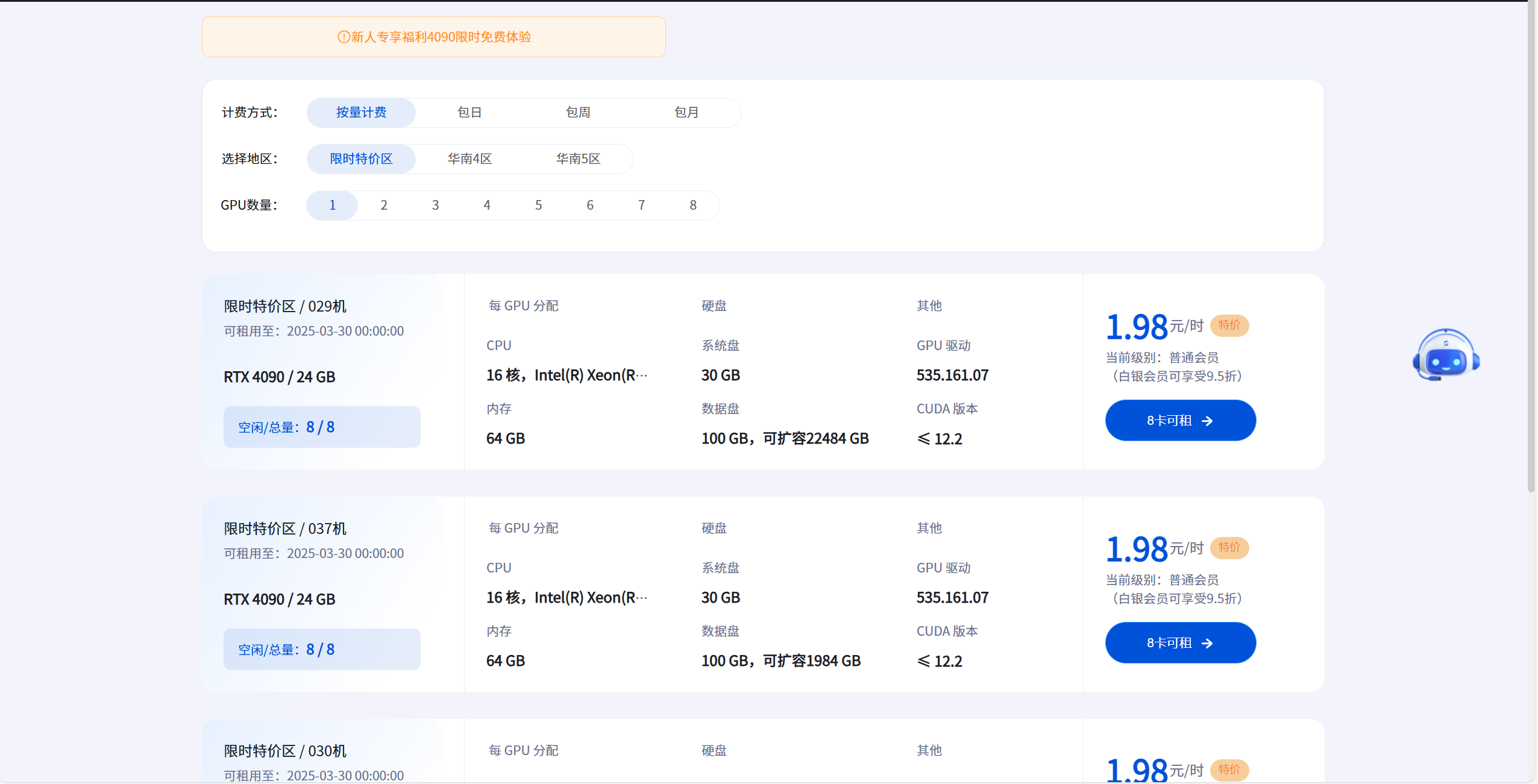
- 选择合适的GPU服务器:
- 创建实例后,即可查看实例列表,并进入实例详情页面:
列表页提供了实例的多种访问方式,包括JupyterLab、Code-Server,LlamaFactory和SSH等。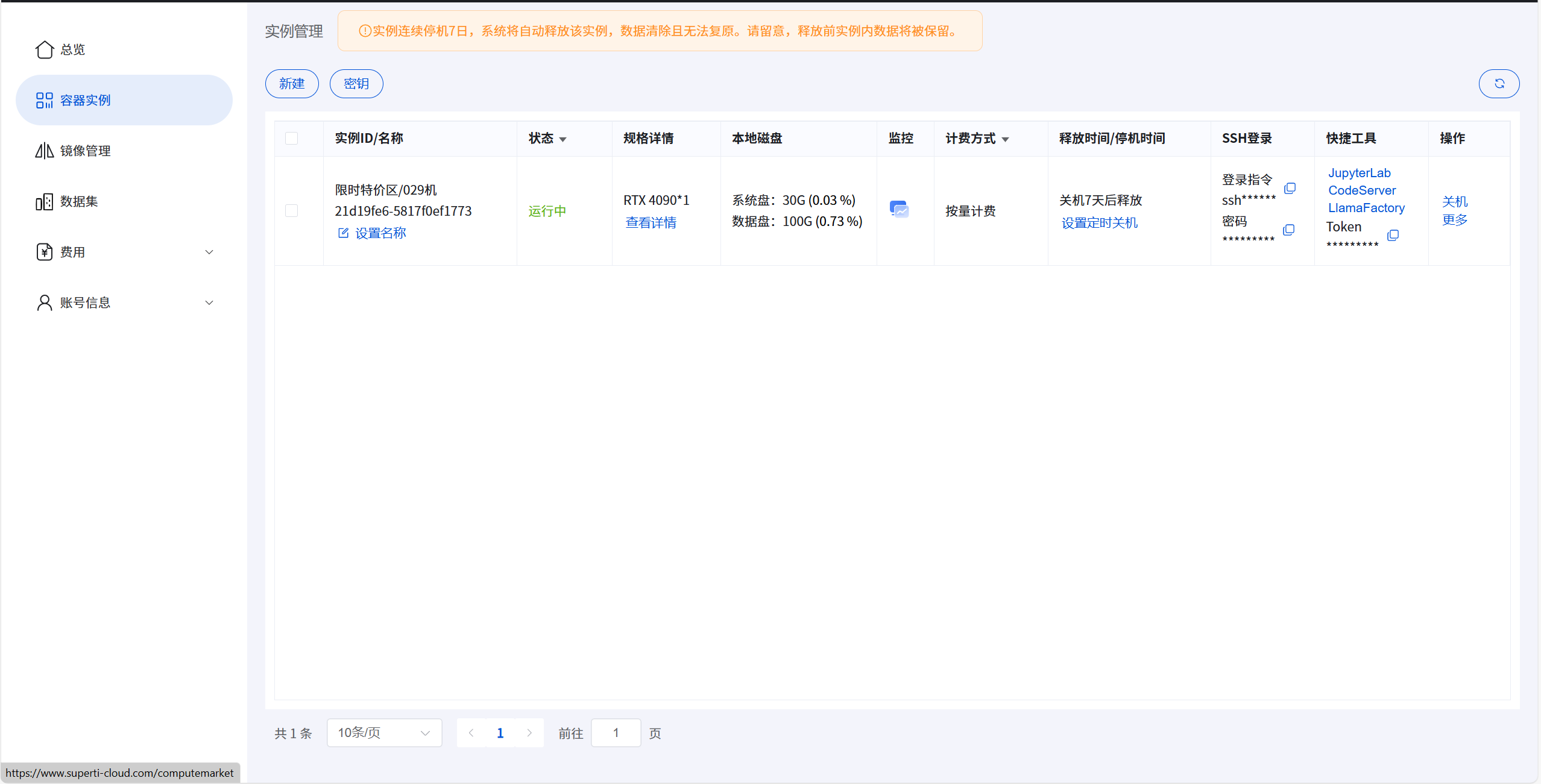
- 访问快捷工具JupyterLab:
打开JupyterLab界面,可以进行代码编辑、运行、调试,查看日志等操作。
- 访问快捷工具Code-Server:
进入WebIDE,默认打开Llamafactory 项目,用户自定义调整内容;调整后需要在终端中,中断运行的Llamafactory 进程并重新运行。
- 访问LlamaFactory:
进入Llamafactory 可视化微调页面,默认已选中模型根据需求配置参数,选择数据集,点击开始即可开始您的模型微调之旅。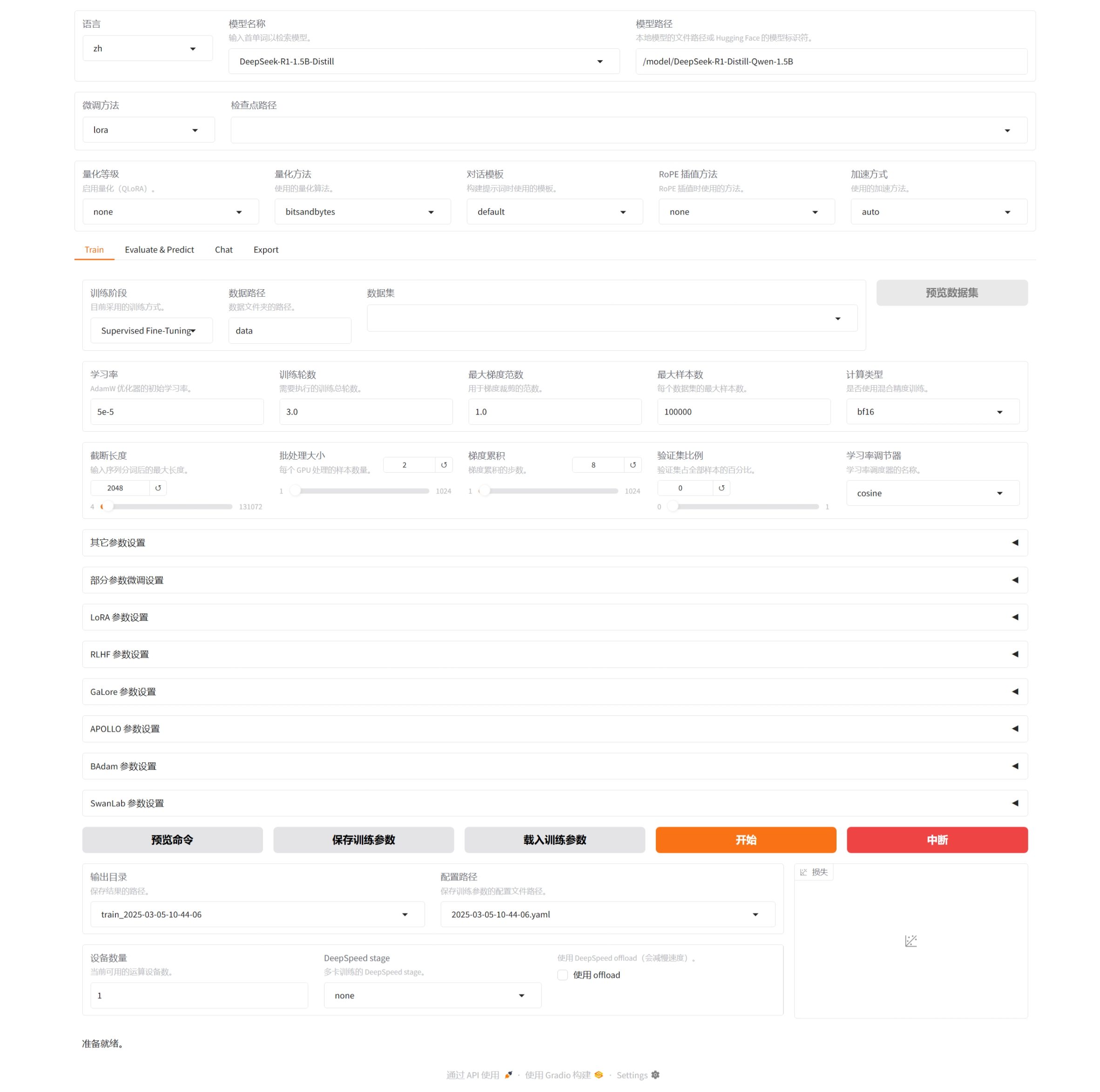
重要提示:RTX 4090 显卡在多卡并行训练时存在硬件限制,不支持 P2P(Peer-to-Peer)通信和 IB(InfiniBand)加速功能。因此在使用 LlamaFactory 进行多卡模型微调之前,需要执行以下步骤:
在终端中使用命令查找LlamaFactory进程,终止找到的进程后设置以下环境变量并重新启动:
shell
root@superti-3043dc6e:~/superti-tmp# ps -efl | grep llamafactory
4 S root 68 63 25 80 0 - 4780800 hrtime 18:58 ? 00:00:22 /usr/bin/python /usr/local/bin/llamafactory-cli webui
0 S root 524 423 0 80 0 - 2392 pipe_r 18:59 pts/2 00:00:00 grep --color=auto llamafactory
root@superti-3043dc6e:~/superti-tmp# kill 68
root@superti-3043dc6e:~/superti-tmp# export NCCL_P2P_DISABLE=1
root@superti-3043dc6e:~/superti-tmp# export NCCL_IB_DISABLE=1
root@superti-3043dc6e:~/superti-tmp# /usr/bin/python /usr/local/bin/llamafactory-cli webui