vLLM:高速推理引擎
SuperTi 平台集成的 AI 推理功能,基于业界领先的 vLLM 高速推理引擎,为您提供一站式的大语言模型(LLM)部署与管理服务。您无需关心复杂的部署环境,只需通过简单的几步配置,即可将选定的模型部署为高性能的在线 API 服务,并对其进行全面的生命周期管理。
创建推理服务
1. 前提条件
在开始之前,请确保您的实例满足以下条件:
- 至少有一张可用的 GPU 卡。
- 实例的镜像支持 AI 训练营工具(通常在镜像名称旁有特殊标记)。
2. 进入 vLLM 配置页面
在“AI 训练营”中找到 vLLM 工具,点击“一键创建”进入配置页面。

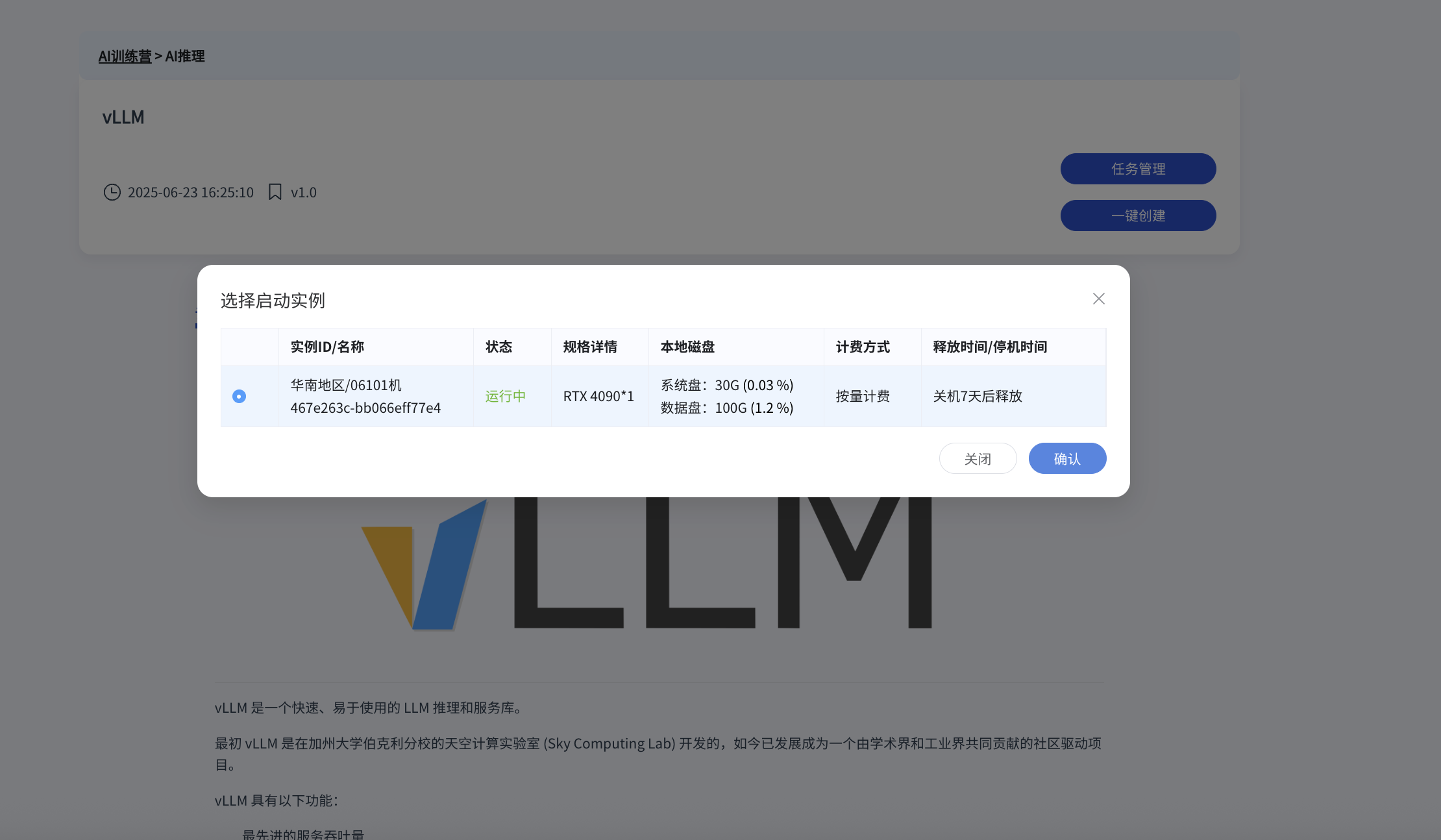
3. 选择实例并配置参数
选择一个符合条件的实例,然后配置推理服务的参数。
您可以根据需求,通过以下两种方式进行配置:
页面配置:在界面上直观地选择模型、设置端口等关键参数。
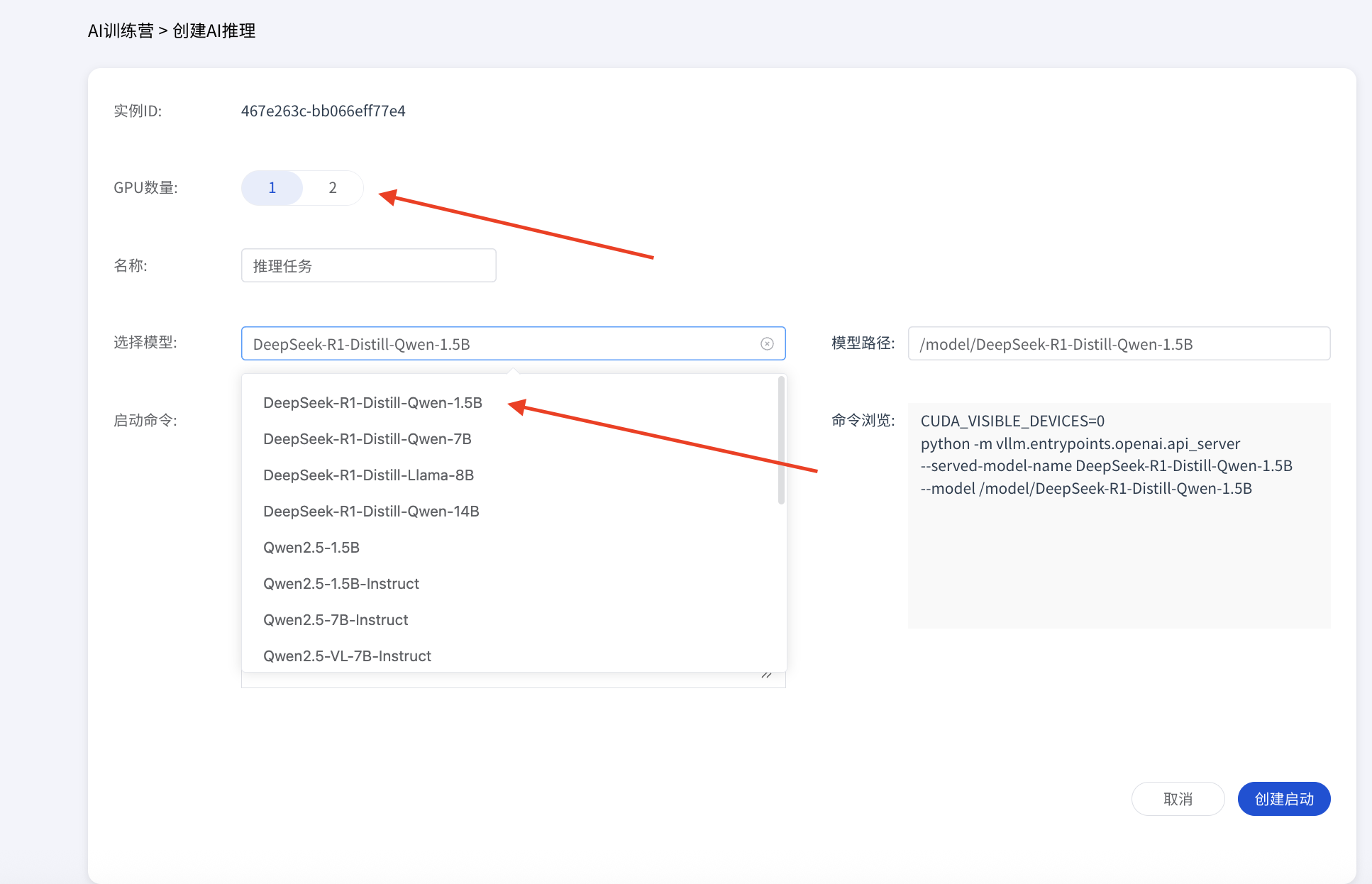 若要使用自定义模型,请在上方填写模型的绝对路径,系统会自动完成路径映射。
若要使用自定义模型,请在上方填写模型的绝对路径,系统会自动完成路径映射。 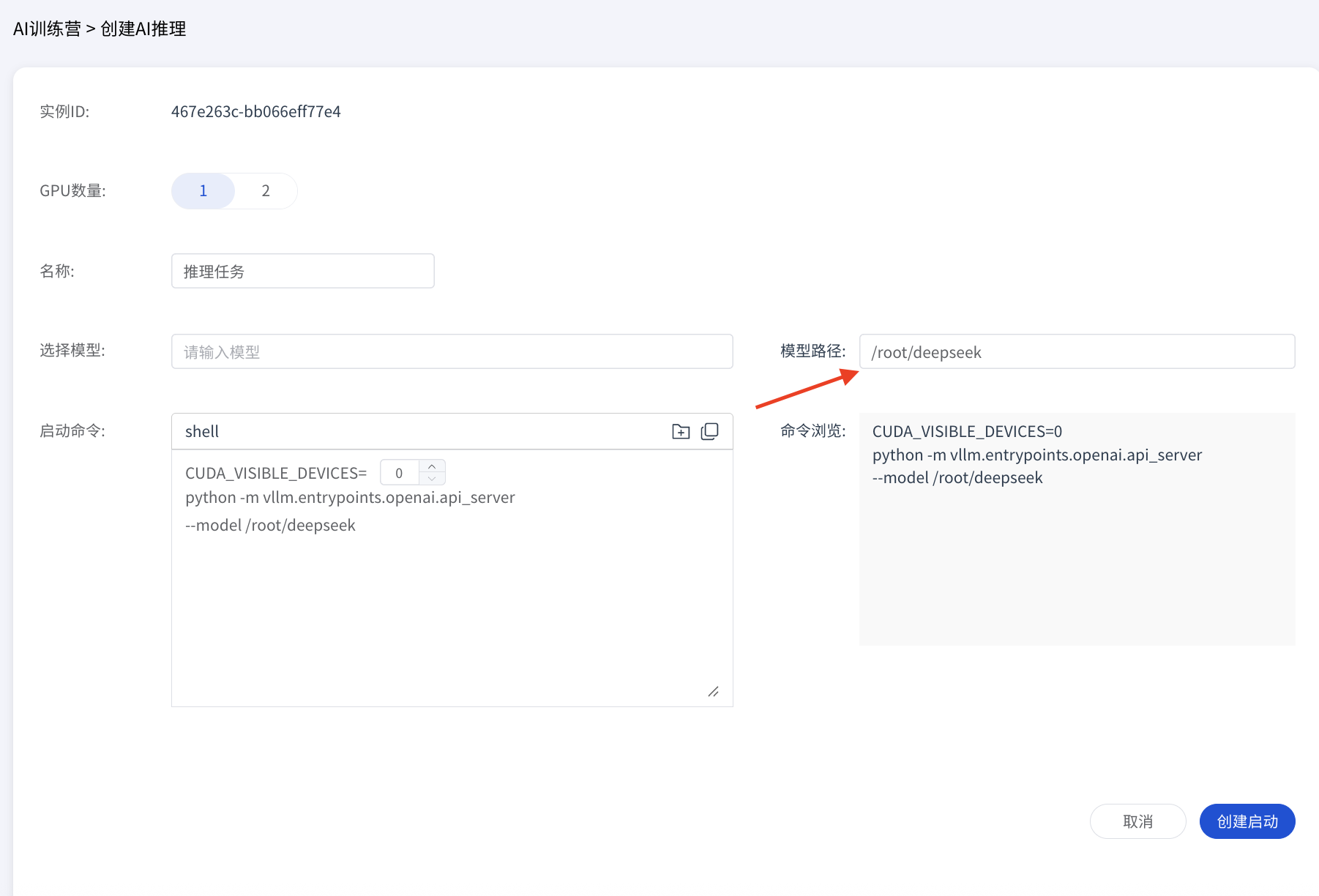
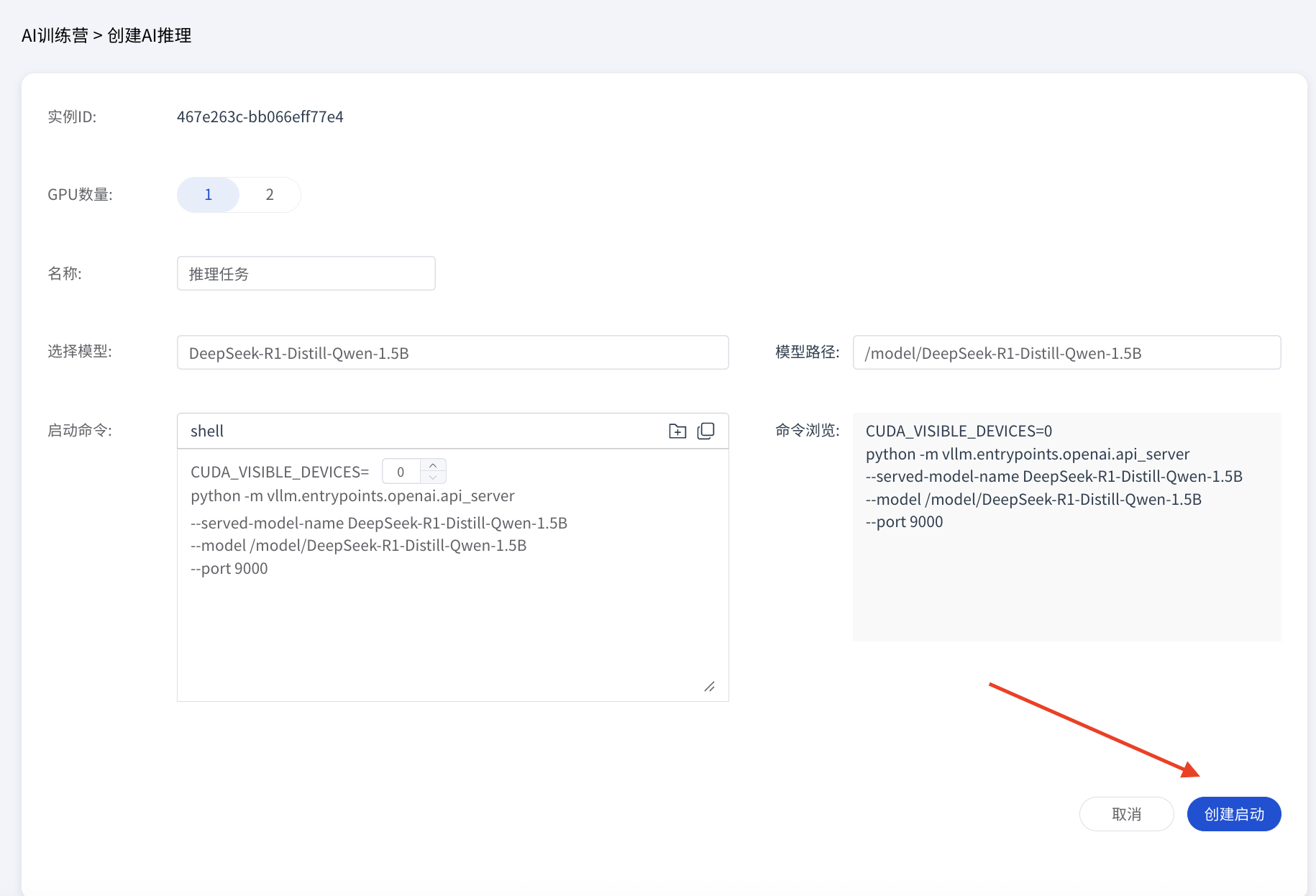
命令行配置:对于高级用户,可以直接编写或粘贴启动命令来精确控制服务配置。
bash# 示例:使用 0, 1, 2 号 GPU 部署 DeepSeek 模型 CUDA_VISIBLE_DEVICES=0,1,2 python -m vllm.entrypoints.openai.api_server \ --model /model/DeepSeek-R1-Distill-Qwen-7B \ --served-model-name DeepSeek-R1-Distill-Qwen-7B \ --port 9000
4. 启动服务
完成配置后,点击“创建启动”按钮,系统将开始部署 vLLM 推理服务。
管理推理服务
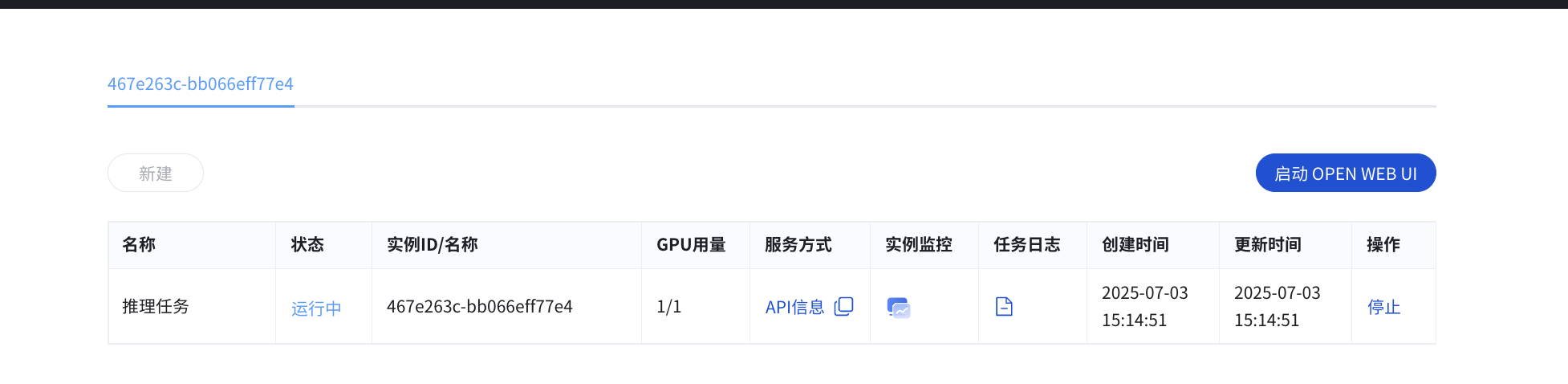
1. 查看任务状态
服务启动后,您可以在 vLLM 的任务列表或实例的详情页面查看和管理您的推理任务。
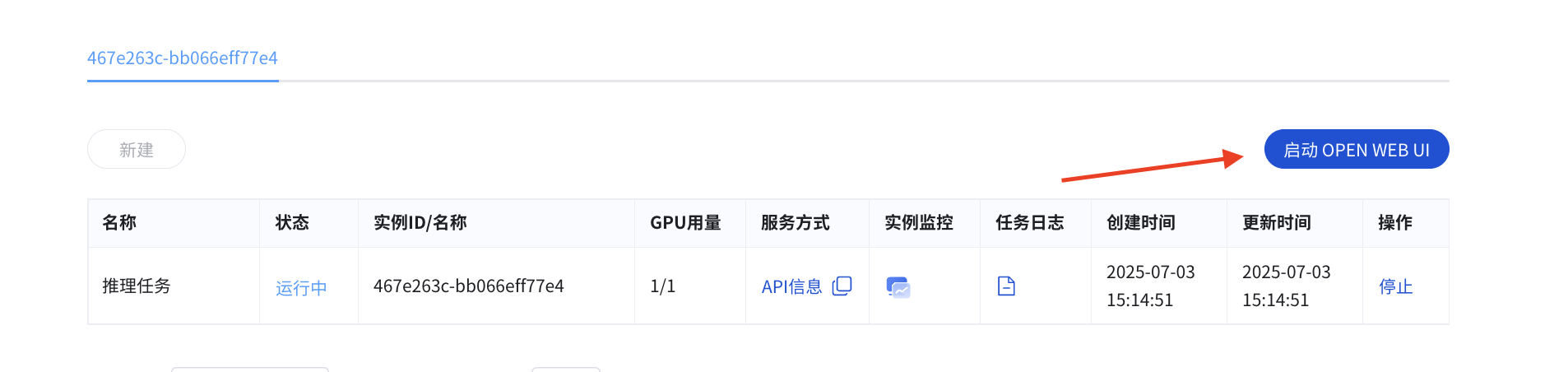
2. 访问 Web UI
对于支持图形化界面的模型,您可以点击“启动 OPEN WEB UI”来访问 Web 界面,方便地与模型进行交互和测试。
3. 注册 Web UI 账户
首次访问时,您需要创建一个本地账户用于登录 Open Web UI。 
4. 配置模型
登录后,进入管理员面板(Admin Panel),准备配置模型。 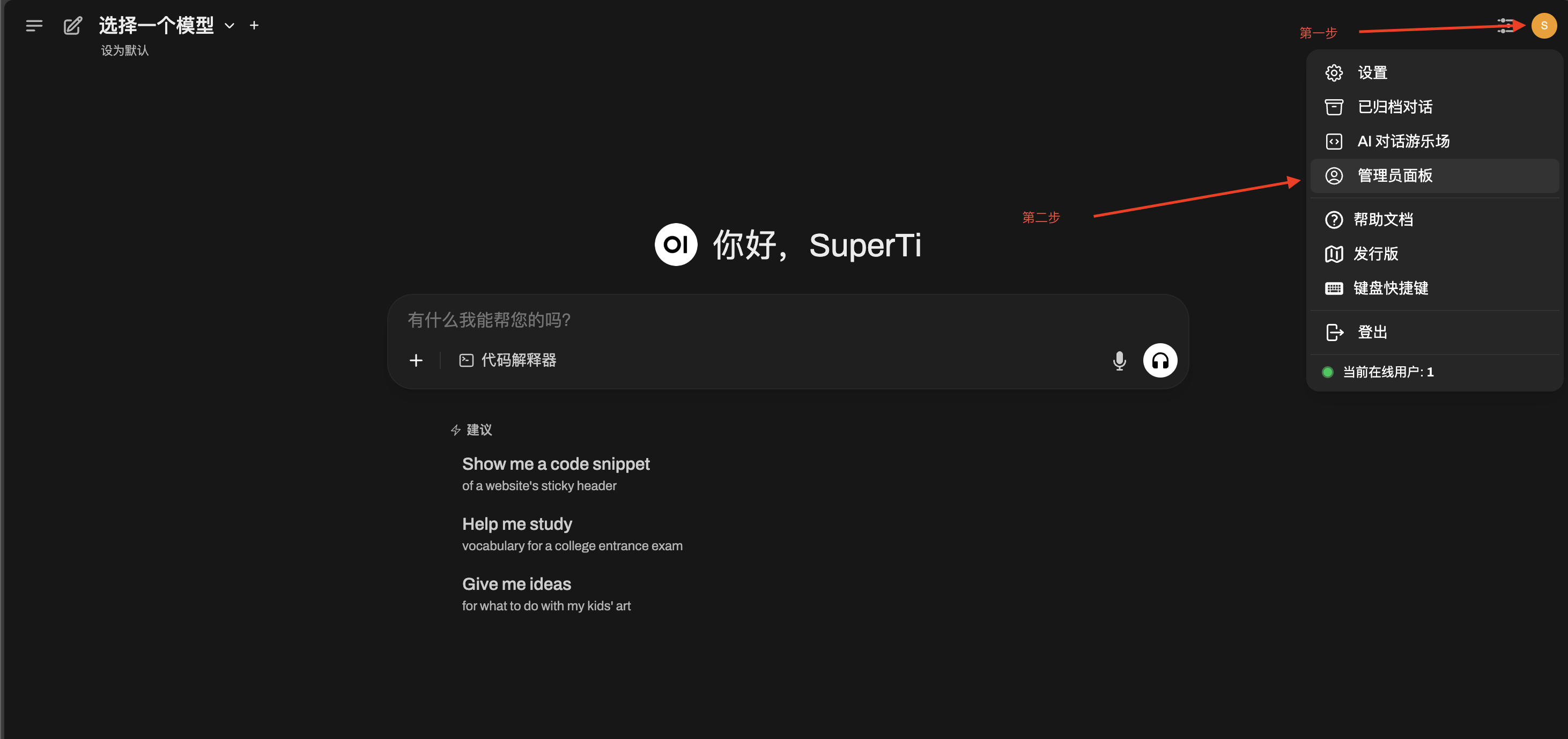
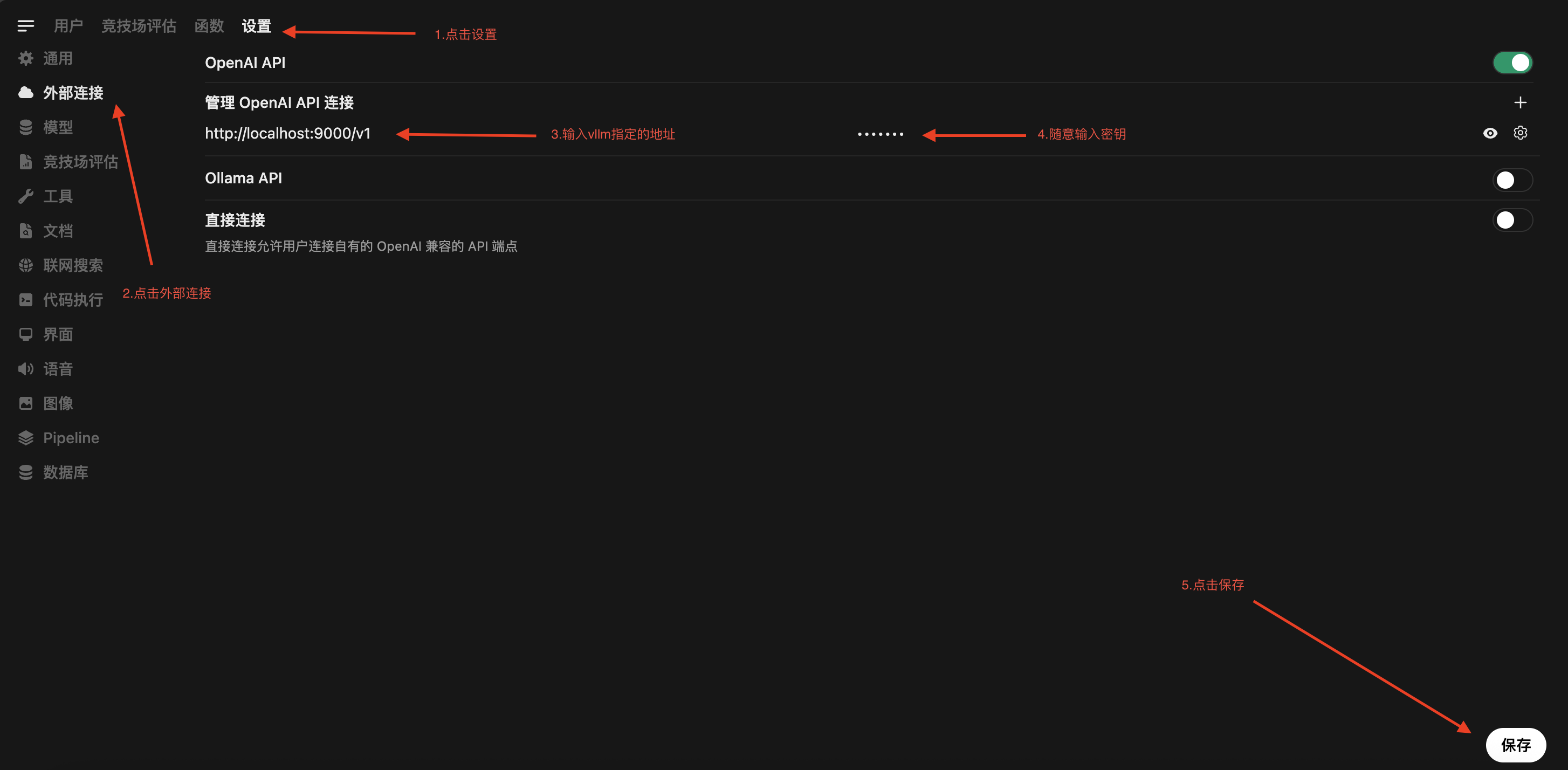
5. 关联 vLLM 服务地址
在模型配置页面,将 vLLM 服务的地址填入。
注意:请务必使用
http协议,而不是https。地址格式应为:http://<实例IP>:<vLLM端口>。
6. 刷新并查看模型
保存设置后,刷新页面。稍等片刻,vLLM 服务中的模型就会出现在模型选择列表中。 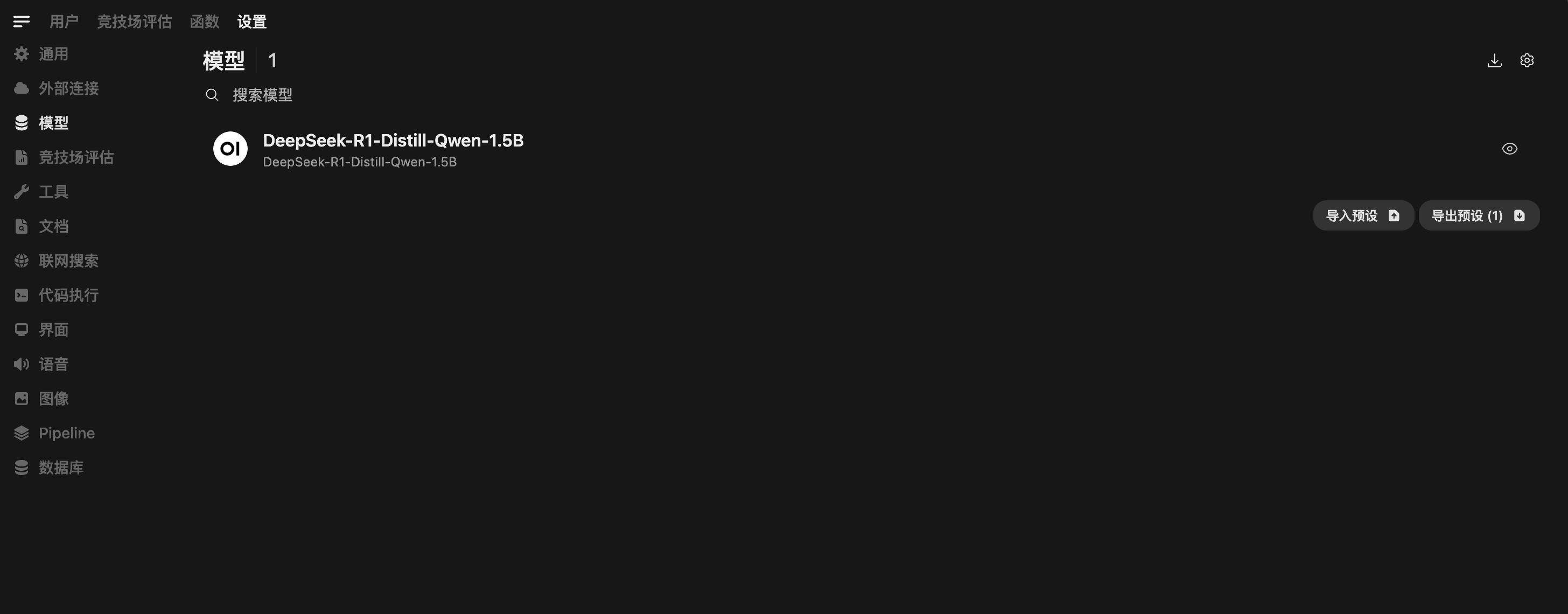
7. 开始对话
现在,您可以选择刚刚加载的模型,开始进行对话和测试。 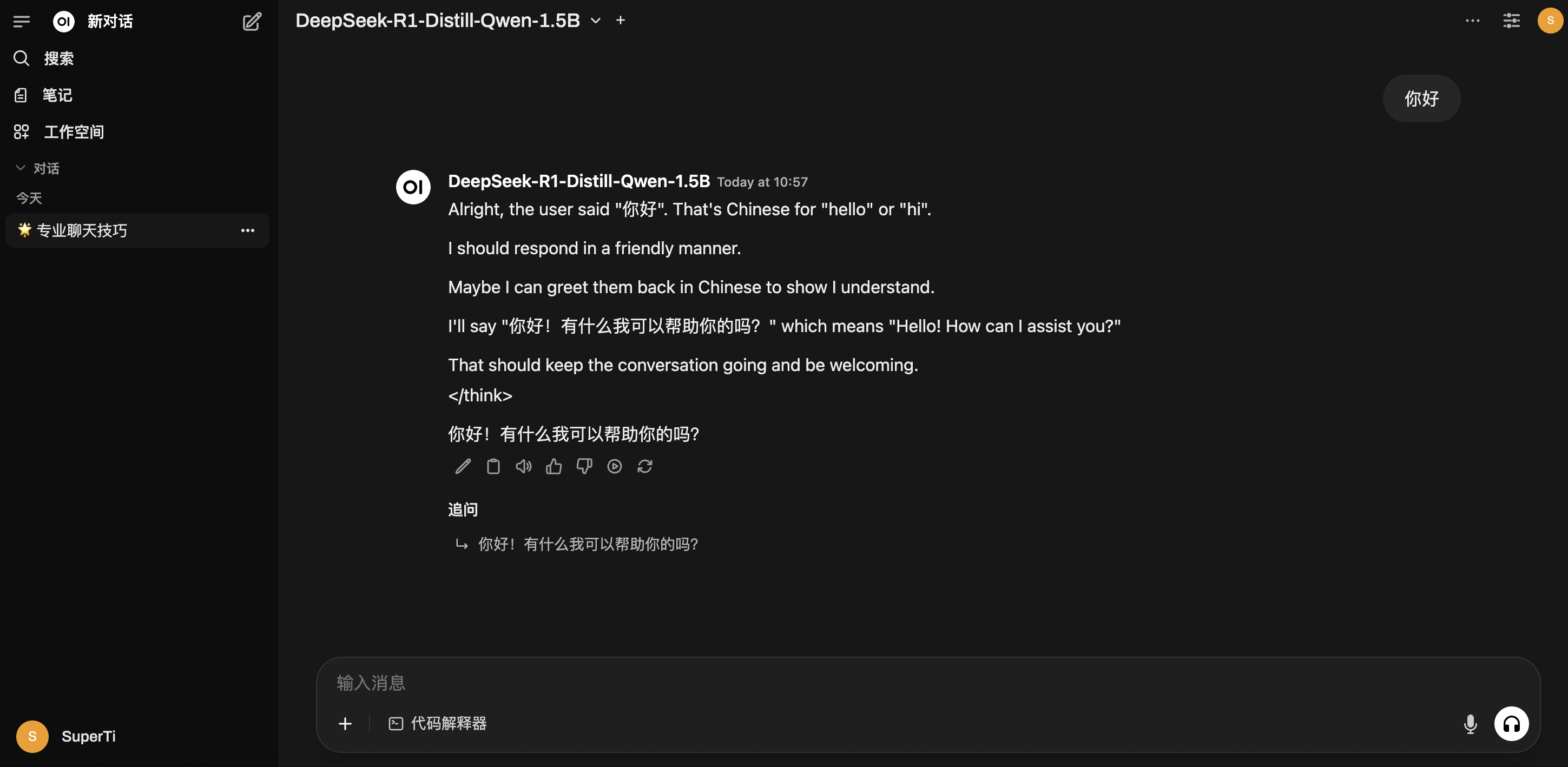
适用场景
- 在线服务:为您的应用程序提供高并发、低延迟的 AI 推理 API。
- API 集成:将强大的语言模型能力无缝集成到现有系统或工作流中。
- 批量处理:高效完成大规模文本生成、摘要、翻译等离线任务。
- 原型验证:快速部署和测试不同模型的实际表现,加速产品迭代。
- 性能评测:对不同模型或硬件配置的推理性能进行基准测试。
更多信息
欲了解更多关于 vLLM 的功能和高级用法,请访问 vLLM 官方文档。